CentOS 7 卸载CUDA 9.1 安装CUDA8.0 并安装Tensorflow GPU版
总阅读次
事前各软件版本:
NVIDIA驱动:390.25
CUDA: 9.1
现在Tensorflow不支持CUDA 9.1,所以采用降级的办法来解决,将CUDA降为8.0,由于NVIDIA驱动可以向下兼容,所以不用卸载NVIDIA驱动。当然也可以不卸载9.1,但是安装目录下cuda软连接指向cuda-8.0即可。
卸载CUDA 9.1 (可选)
1 | cd /usr/local/cuda-9.1/bin |
安装CUDA 8.0
从官网下载CUDA 8.0 ToolKit。
这里我下载的是cuda_8.0.61_375.26_linux.run,并下载补丁cuda_8.0.61.2_linux.run。
进入root用户,将上述两个文件拷贝到/root(或其他地方),直接用root用户较方便。
1 | chmod +x cuda_8.0.61* # 加上执行权限 |
然后可以到Samples目录,先make编译,然后到bin下找到deviceQuery,执行./deviceQuery,
如果安装成功应该会显示类似如下信息:1
2
3...(省略)
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 9.1, CUDA Runtime Version = 8.0, NumDevs = 2, Device0 = Tesla K80, Device0 = Tesla K80
Result = PASS
安装cuDNN
cuDNN是NVIDIA专为Deep Learning应用开发的支持库。
我们打算安装Tensorflow 1.4.0,该版本要求libcudnn.so.6,所以下载v6版本的cuDNN。
到这里下载
下载:cudnn-8.0-linux-x64-v6.0.tgz。
将其传到/usr/local目录下,然后解压即可:1
tar -zxvf cudnn-8.0-linux-x64-v6.0.tgz
这样就成功安装了CUDA 8.0这一套,但是驱动仍然用的高版本驱动390.25,不过应该没关系的吧。
添加环境变量
1 | vim ~/.bashrc |
安装Tensorflow
1 | pip install tensorflow-gpu==1.4.0 |
试一把,import tensorflow成功即说明CUDA,cuDNN安装完成,且版本没问题。
运行两个GPU的例子:1
2
3
4
5
6
7
8
9
10
11
12
13import tensorflow as tf
c = []
for d in ['/device:GPU:0', '/device:GPU:1']:
with tf.device(d):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3])
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2])
c.append(tf.matmul(a, b))
with tf.device('/cpu:0'):
sum = tf.add_n(c)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Runs the op.
print(sess.run(sum))
输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16MatMul_1: (MatMul): /job:localhost/replica:0/task:0/device:GPU:1
2018-03-12 19:22:00.759031: I tensorflow/core/common_runtime/placer.cc:874] MatMul_1: (MatMul)/job:localhost/replica:0/task:0/device:GPU:1
MatMul: (MatMul): /job:localhost/replica:0/task:0/device:GPU:0
2018-03-12 19:22:00.759079: I tensorflow/core/common_runtime/placer.cc:874] MatMul: (MatMul)/job:localhost/replica:0/task:0/device:GPU:0
AddN: (AddN): /job:localhost/replica:0/task:0/device:CPU:0
2018-03-12 19:22:00.759100: I tensorflow/core/common_runtime/placer.cc:874] AddN: (AddN)/job:localhost/replica:0/task:0/device:CPU:0
Const_3: (Const): /job:localhost/replica:0/task:0/device:GPU:1
2018-03-12 19:22:00.759126: I tensorflow/core/common_runtime/placer.cc:874] Const_3: (Const)/job:localhost/replica:0/task:0/device:GPU:1
Const_2: (Const): /job:localhost/replica:0/task:0/device:GPU:1
2018-03-12 19:22:00.759145: I tensorflow/core/common_runtime/placer.cc:874] Const_2: (Const)/job:localhost/replica:0/task:0/device:GPU:1
Const_1: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-03-12 19:22:00.759167: I tensorflow/core/common_runtime/placer.cc:874] Const_1: (Const)/job:localhost/replica:0/task:0/device:GPU:0
Const: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-03-12 19:22:00.759185: I tensorflow/core/common_runtime/placer.cc:874] Const: (Const)/job:localhost/replica:0/task:0/device:GPU:0
[[ 44. 56.]
[ 98. 128.]]
从输出结果看,确实使用了两块GPU,基本说明可以同时使用两块GPU。
进一步的例子:CIFAR10多GPU训练
进一步地,我们采用Tensorflow的tutorial中的一个例子来验证多块GPU卡带来的加速效果。
运行cifar10多GPU训练,1
python cifar10_multi_gpu_train.py --num_gpus=2
可以用如下命令设置每隔一秒查看一下GPU状态:1
nvidia-smi -l 1
或者使用gpustat工具,更简洁的观察GPU动态状态变化:1
2pip install gpustat
watch --color -n1 gpustat -cpu
可见在两块Tesla P100上,训练吞吐率大约为 34000 image/sec 左右,在单块 GPU 上,训练吞吐率大约最高为 19000 image/sec。从目前结果看来,虽然两块GPU能够大大加速训练,但是毕竟还是无法做到标准的线性的加速。
本地查看远程服务器Tensorboard (Windows, Linux)
核心思想是利用SSH的转发/隧道机制。Tensorboard起在远程服务器本地6006端口,我们本地用一个端口去访问比如16006,我们建立一个隧道,将我们对16006端口的访问转发到远程服务器的6006端口即可。
一般本地和远程在一个局域网内,可以如下做:
- 在Lunux下:
1 | ssh -L 16006:127.0.0.1:6006 user@server.address |
建立本地16006端口到服务器6006端口的正向转发
- Windows下:
Windows 10中除了一个开发者模式,内嵌一个linux系统,可以进入如上做。但是一般我们在Windows下还是用putty,Xshell,MobaXterm等远程登录软件为主,这里以Xshell为例。
步骤为:
1、新建一个会话指向服务器,设置属性,点“隧道”,然后点中间的“添加”,添加的信息如下:
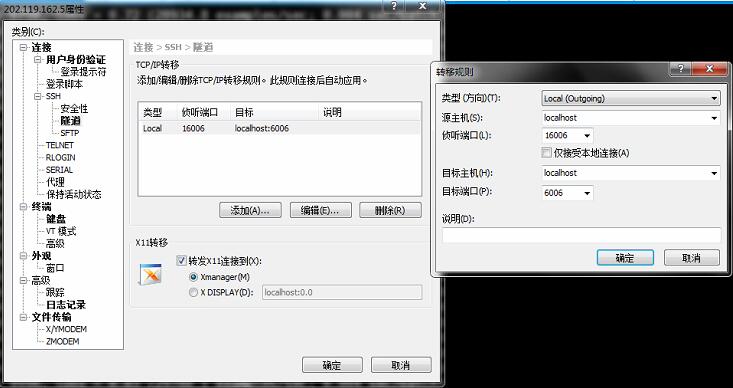
X11转移那里打钩,也必须保证远程服务器允许X11转发,具体的,在/etc/ssh/sshd_config中设置X11forwarding为yes。
这样即建立了一个隧道。然后在服务器上启动Tensorboard,在本地浏览器打开http://127.0.0.1:16006即可访问TensorBoard。
- 客户端位于外网
当然还有一种情况就是客户端位于外网,无法直接建立隧道。
此种情况下 [1],服务器可以通过IP地址寻址客户端,所以在服务器端建立与客户端的反向链接。通过-N -f后台运行。具体命令为:
在服务器主机上执行:1
ssh -f -NR <client_port>:localhost:<server_port> [username@]<client_ip_address>
除了本地查看Tensorboard,也可以启动服务器桌面来直接看Tensorboard。具体可以安装VNC Server和Viewer。
安装VNC (Server & Viewer)
1、服务器安装VNC Server: yum -y install tigervnc-server
2、配置分辨率和用户登录信息1
2
3
4# vim /lib/systemd/system/vncserver@.service
写入
VNCSERVERS="2:root"
VNCSERVERARGS[2]="-geometry 1024x768"
3、下载VNC Viewer,VNC Viewer连接,可能出现Timeout的问题,可能是服务器设置了防火墙,如下命令关闭:1
2
3
4iptables -I INPUT -p tcp --dport 5801 -j ACCEPT # 浏览器
iptables -I INPUT -p tcp --dport 5901 -j ACCEPT # VNC Viewer
或者进入/etc/sysconfig/iptables添加一行:
-A INPUT -m state --state NEW -m tcp -p tcp --dport 5900:5903 -j ACCEPT
黑屏解决方案:
在/root/.vnc/xtartup文件中:1
2
3
4
5
6
7
8
9# unset SESSION_MANAGER
# exec /etc/X11/xinit/xinitrc
注释掉以上两行,添加如下几行:
[ -x /etc/.vnc/xstartup ] && exec /etc/.vnc/xstartup
[ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources
xsetroot -solid grey #vncconfig -iconic &
xterm -geometry 80x24+10+10 -ls -title "$VNCDESKTOP Desktop" &
twm &
gnome-session &
总结
本文主要讲述了CUDA 8.0的安装细节,TensorFlow的安装,多GPU训练实例,以及远程服务器TensorBoard查看,以及VNC(Virtual Network Console)的服务端和客户端的安装。
更多的一些错误及解决方案因为目前还解决不全,一律放到后面的《TensorFlow, GPU错误及优化集锦》
References
[1] 远程使用内网服务器的tensorboard和jupyter notebook
[3] 跑深度学习代码在linux服务器上的常用操作(ssh,screen,tensorboard,jupyter notebook)


