Ray 论文解读
总阅读次
Ray是UC.Berkerly去年(2017)提出来的一个分布式执行引擎。Ray主要面向未来交互式的AI,如强化学习,提供任务并行和高速的任务调度。用户可以借助Ray迅速的进行任务并行来加速模型训练和推理。本文对Ray论文进行解读,以进一步地剖析了解Ray的运作原理,灵感来源,优缺点,在分布式机器学习框架中所处的位置,以及论文的写作,阐述过程等等。希望能给大家带来一些启发和思考。
摘要(Abstract)
摘要部分简洁明了。首先说下一代的AI应用会持续地与环境进行交互,即走向交互式学习,在交互中学习,故而对支持AI的底层系统提出了新要求。论文阐述了这些要求(如性能,灵活性方面的要求),并提出Ray这一框架来满足这些要求。Ray实现了动态任务图计算(dynamic task graph computation),支持任务并行(task-parallel)和Actor编程模型。
为了满足性能(Performance)要求,Ray提出了一种逻辑中心控制状态板的概念,采用分片的分布式存储系统(Redis)来实现,以及提供了一种新颖的自底向上的分布式调度器。
实验表明,Ray可以实现次毫秒级的任务调度延迟,任务吞吐量大,在很多challenging的benchmark上得到了加速,并且自然且高效地适配新兴的一类强化学习应用与算法。
摘要部分的逻辑非常清晰,首先说明问题,问题提出的新要求,为了解决问题,满足要求,我们提出xx,xx具有…的性质,提出了…idea,实验表明,xx具有良好的效果。简单来说就是:问题-方法-效果三大块,看起来很舒服。
介绍(Introduction)
(Situation) AI目前风生水起,应用广泛。过去主要集中在监督学习上,离线训练在线部署,如今领域(AI,ML)逐渐成熟,呈现新需求:AI系统需要在动态环境中不断响应变化,与环境交互来学习。这种模式天生与强化学习契合。强化学习应用也取得了一些很好的效果。
强化学习与监督学习有三点不同:
- 强化学习依赖大量的模拟动作
- 强化学习的计算图是异构的,动态演化的,每部分的计算时间可能差别很大
- 需要快速作出响应
(Question) 总的来说,我们需要这样一个计算框架:支持异构的、动态的计算图,每秒处理百万级任务数,且只有毫秒级的延迟。
(Conflict) 已有的集群计算框架无法充分满足这些要求。
MapReduce, Spark, Dryad, Dask, CIEL 既不能提供强化学习应用需要的吞吐量,也不能达到其要求的延迟。
Tensorflow, Naiad, MPI, Canary 通常假设计算图是静态的。
(Answer) 本文提出Ray,一个新的满足这些条件的集群计算框架。
为了满足:
- 条件1:异构动态工作流 => Ray实现了动态任务图计算模型,类似于CIEL,并在CIEL的任务并行之上提供了一个actor编程模型,actor抽象使得Ray能够支持有状态组件,封装第三方服务。
【什么是actor抽象?】actor可以理解为一个第三方服务的代理,或者一个类,类中包含了成员变量和方法,成员方法可以调用某些第三方服务,故而actor相当于对第三方服务的一个封装和一个抽象,真正的实现可以是各种第三方服务。在编程语言中的实现就是像类一样实现,只不过在类定义前加一个@ray.remote而已。
- 条件2:高性能 => 采用一种新的分布式架构,可以实现良好的水平扩展。主要基于两个idea:
1)中央控制板,系统的所有控制状态都属中央控制,各个组件可以实现无状态,从而实现良好的水平扩展和容错。
2)自底向上的分布式调度器。即有一个全局调度器(global scheduler),每个节点有本地调度器(local scheduler),本地调度器可以选择本地调度,也可以将任务转发给global scheduler,让global scheduler来进行调度。
【问题一】看到这里,读者可能会问,何时决定选择本地调度还是往上层转发呢?采何种标准决定到底是本地调度还是往上层转发呢?这是后续需要回答的问题。
可以看到,介绍部分的基本逻辑清晰,我们采用SCQA/SQCA分析法来分析,首先介绍现在的处境(Situation),然后提出问题(我们需要xxx)(Question),然后是冲突(Conflict),即现在没有满足这些条件的框架,最后是答案(Answer),即我们提出Ray…。这种写法可以叫SQCA法,也可以调一下顺序,按SCQA的顺序来写。
论文有如下贡献:
- 提出当前AI系统的一些要求
- 提出了actor抽象
- 提出具有高度水平扩展性的一种架构,并构建Ray来实现。
【问题二】水平扩展的方式,能否支撑大数据?
Ray的架构:
Motivation and Requirements
强化学习工作流是Ray设计的主要动机,也是本文重点。
以强化学习为例,本文将新型系统的要求分为三大类:
- Flexibility
Flexibility又分为几个方面:
一个是并发任务的异构性,有以下三种,功能不同,时长不同以及资源类型不同。如视频的处理和文本的处理就不是同一个功能,在一个时长,执行的计算也不一样。资源类型指的是GPU或者CPU等。
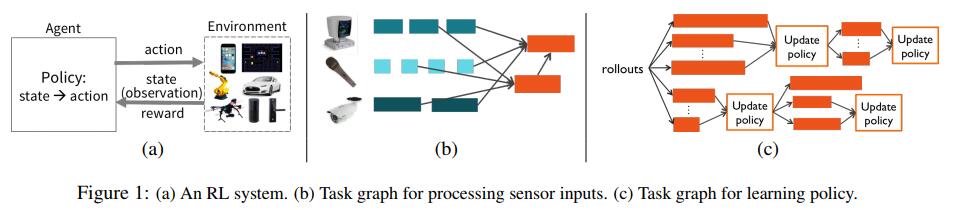
另一个是执行图的通用性和动态性。
上面这些要求,BSP的模型(如Hadoop MapReduce, Apache Spark)是无法满足的。
在BSP模型中,每个Stage执行的计算通常是相同的,故而计算所需的时间也相似。
- Performance
机器人与环境交互的场景中,需要在ms级别采取反应给出action,所以调度最好在1ms内完成,否则会成为一块拖累。鉴于集群中核数达几百几千甚为常见,调度吞吐量应该要很大。
所以其实Ray对任务的快速调度做得比较好,能够做到非常快速的调度,因为就是针对这个需求设计的。
- Ease of Deployment
写并行程序本来就不容易。简化开发对于一个系统的成功来说是至关重要的。
易用性包括几个方面:
- 确定型的重放以及容错机制。
- 已有算法易并行。包括对Python语言的支持,以及提供第三方服务的紧密集成,这方面采用actor抽象来封装第三方服务。
编程模型和计算模型(Programming and Computation Model)
不同于其他系统,Ray提供了actor和task-parallel两重编程抽象。
不像CIEL,只提供任务并行抽象,或Orleans,只提供actor抽象。
编程模型
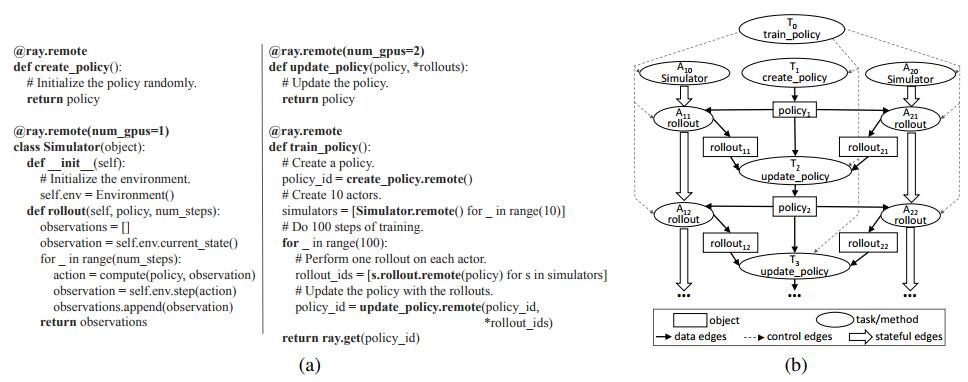
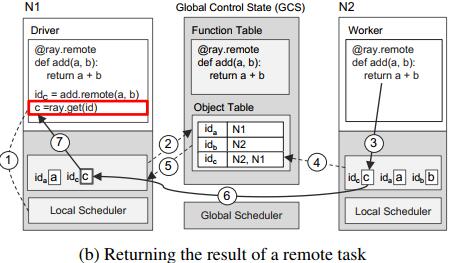
当一个带有@remote注解的remote函数被调用,会立即返回一个future对象,然后调用ray.get即可得到结果。
比如说1
2
3
4
5
6
7
8
9
10
11
12
13import time
import ray
ray.init()
def f():
time.sleep(1)
return 1
# Execute f in parallel.
object_ids = [f.remote() for i in range(4)]
results = ray.get(object_ids)
f.remote()调用运行时,将返回一个future对象,存储在object_ids中,调用ray.get(object_ids)可以得到返回值的列表。
remote函数操作的数据是不可变的对象,remote函数是无状态,无副作用的,使得幂等性得以保证,从而简化了容错的处理。
为了满足一些条件,Ray所提出了的编程模型如下:
处理不同时长的任务,采用了
ray.wait(),这个调用的意思是,运行很多的task后,可以设定等待的个数,当一定个数的任务执行完成时,其他不再执行,整个调用也结束,返回“等待的”一些future的子集。思想类似于Spark的backup机制,即运行同样的多个任务,哪个先完成就用哪个的结果,其他的马上停止,不再考虑。为了解决资源异构任务,在Ray中,开发者可以自己制定remote函数所需的资源量,资源种类有CPU,GPU(官方支持),以及自定义的resources。同样地,Actor也可以制定资源,但是目前Ray在调度Actor的时候,只根据GPU资源来调度。见这里
为了提升flexibility,在Ray中,remote函数可以相互嵌套,即在remote函数中可以调用remote函数,这样可以充分提高可扩展性,同样提高灵活性。
为了容易部署和保证高效性,Ray中涉及了Actor抽象,可以用来封装第三方服务。
计算模型
Ray采用了动态计算图机制,即一旦输入准备好了,就自动触发remote函数或者actor方法执行。
那么Ray是如何将一个用户程序转换成计算图的呢?
不考虑actor的情况下,整个计算图的节点只包含两种类型的对象,数据对象和remote函数调用,或者称为task。
计算图有两种类型的边,数据边(data edge)和控制边(control edge)。
具体如下:
数据对象用D表示,task用T表示。
如果任务T产生输出D,那么T->D建一条边
如果D是T的输入,那么D->T有一条边
如果T1中调用了T2,那么T1->T2有一条边
考虑actor的情况下,增加一种数据对象即actor的方法(Method),增加一种边,叫做有状态边(stateful edge),表示一种执行的先后顺序。
因为同一个actor中,方法的执行是顺序的,无法并行,Mi->Mj的边即表示先执行方法Mi,再执行方法Mj。
有状态边有两种好处,一是使得我们可以把actor嵌入到无状态的任务图中,因为actor维护着自己的一个调用链和状态。二是,有状态边可以用来维护世系(lineage)信息,世系可以帮助Ray重建数据对象,包括remote function创建的或是actor method创建的。
架构(Architecture)
架构包括两层,应用层(Application Layer)和系统层(System Layer)。
应用层
应用层包含三种进程,Driver,Worker,Actor。
Driver用来执行用户程序,即python xx.py产生的进程。
Worker用来执行task,task(remote function)可以由driver或者是其他worker调用,每个机器上运行ray start后会启动0个或多个Worker【待详述】。Worker是无状态的,由系统层指配task。
当一个remote函数声明的时候,函数会自动发布到所有worker。【待详述】
Actor是一个有状态的进程,当其方法被调用时执行,Actor一经启动在某个节点上,则负责执行所有该actor的方法调用。
Actor是有driver或者worker显式地初始化得到的,即采用actor_name.remote()的方式。
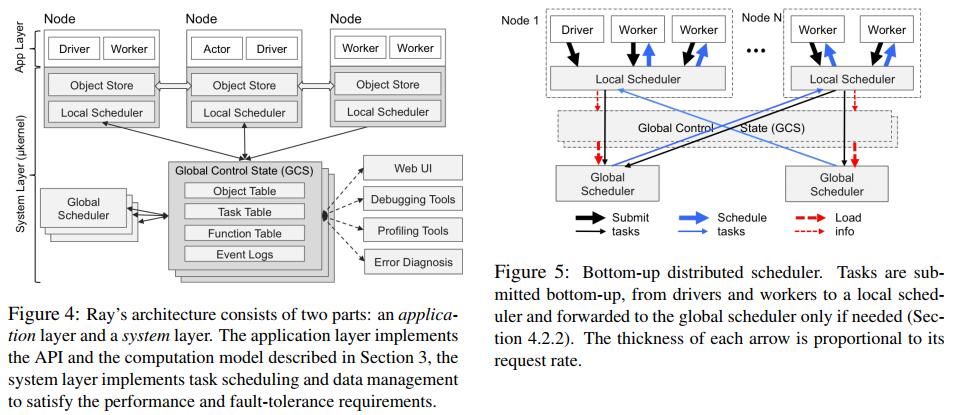
系统层而言,提供了三个组件,每个组件都具有水平可扩展性以及容错机制,来保证前述性能目标和容错目标。
三个组件分别是:全局控制状态(global control state),分布式自底向上调度器(distributed bottom-up scheduler),分布式对象存储(distributed object store)。
系统层-Global Control State
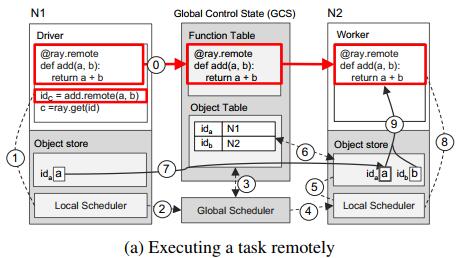
全局控制状态(GCS)是一个中心化的存储,使用Redis实现,负责存储task描述,remote方法代码,计算图,对象的位置,以及每个调度事件。
将所用控制状态集中存储,有这么几个好处:
1)使得集群中其他组件、节点可以无状态。这样的话可以大大提升水平扩展的能力。
2)简化了容错。
3)方便对程序debug,profile。
当然,集中式存储带来的隐忧就是瓶颈问题,基于Redis,可以做分片(sharding)来缓解单点瓶颈。并且为每个分片提供热副本(hot replica)【是什么?】来容错。
鉴于在Ray中,每个task, object, method等都有一个唯一的伪随机ID与其一一对应,使得分片间能够更好地负载均衡。
系统层-Distributed Bottom-Up Scheduler
分布式自底向上调度器(distributed bottom-up scheduler),负责任务的调度。Ray启动时,会启动一个全局的调度器global scheduler,实现上是一个redis server,会在每个从节点上启动一个local scheduler,每个节点上提交的task率先提交给各自的local scheduler进行调度,如果local scheduler调度不了,则上推给global scheduler,进行集群全局范围的调度。
Ray这样设计的目标是调度可扩展性以及快速,低延迟的调度。这样设计带来的好处就是Ray调度任务非常之快。
那么Ray这样设计的灵感来自于哪里呢?
通常的分布式集群计算框架实现的都是中心化,集中式的调度,如Hadoop, Spark, CIEL, Dryad等。这种方式虽然简化了设计,但是扩展性不好。
提升调度扩展性有几种方式:
1)批量调度。调度器批量提交任务给worker节点,以摊销提交任务带来的固定开销。Drizzle框架实现的就是这种。
2)层次调度。即全局调度器(global scheduler)将任务图划分到各个节点的本地调度器(local scheduler)。Canary框架实现了这种调度。
3)并行调度。多个全局调度器同时进行任务调度。这是Sparrow框架所做的。
但是他们都有各自的缺陷。
批量调度仍然需要一个全局调度器来处理所有任务。
层次调度假设任务图是已知的,即假设任务图是静态的。
并行调度假设每个全局调度器调度独立的作业。
Ray希望做到的是高可扩展性,处理动态任务图,并且可能处理来自同一个作业的任务。
Ray的自底向上调度器类似层次调度,不同的是,一个节点生成的task首先提交到各自的local scheduler,由local scheduler进行调度。除非本地节点过载了,或者本地节点不能满足task的资源需求,或者task的输入不在本地节点等因素出现,否则本地节点可以完成调度。
其实最后一条,task的输入不再本地,仍有方式在本地调度,因为object store可以实现快速的数据对象转运。
看到这里,读者可能想问,Ray的local scheduler是怎样判断是否该调度到本地节点还是上推到global scheduler呢?
Ray是这样处理的,local scheduler会维护一个任务队列(task queue),每次调度任务时它会检查当前任务队列的长度,如果超过一定的阈值,那么认为本机过载了,不在调度当前任务而是将其转给上层全局调度器。
这个阈值为0,则调度为集中式的调度,全靠global scheduler负责。
这个阈值为无穷大,则调度为去中心化的分布式调度,所有任务都有本地节点负责。
在框架设计上,local scheduler每隔一段时间会发送心跳包给GCS,注意不是直接发送给global scheduler,心跳包中会包含local scheduler的负载信息,GCS收到以后记录此信息,转发给global scheduler。
当收到local scheduler转发来的任务时,global scheduler使用最新的负载信息,以及人物的输入数据对象的位置和大小,来决定将task分发到哪个节点去运行。
如果global scheduler成为了瓶颈,那么采用多个副本,local scheduler随机选择一个global scheduler去转发任务。
系统层-Distributed Object Store
remote函数(task)的输入和输出数据都存储在Distributed Object Store中。
调用一个函数时,其输入首先被隐式执行ray.put,存储object store中,其输出也会被放入object store中,函数返回一个object id为该输出数据的唯一id,调用ray.get(object_id)才可获得任务返回的实际数据。
同一个节点上使用共享内存(shared memory)来实现object store,这使得两个不同的worker进程或者driver和worker之间能够零拷贝(zero copy)地访问共同的数据。具体实现采用了Apache Arrow中的plasma store。Apache Arrow是一种跨平台的内存数据交换格式。可参看介绍,等。
如果一个task,其输入不在本地,那么object store会把数据从所在地拷贝到本地,这样可以避免热数据带来的瓶颈,同时可以加快程序执行速度,因为直接在本地内存中操作。当然,数据的传送开销也是免不了的。这也将提升计算受限工作流的吞吐量,计算受限是许多AI应用共有的特征。
为了简化系统设计,简化容错,Ray像其它内存计算系统如Spark, Dryad一样,其操作的数据是不可变的(immutable),即存储在object store中的数据不能改变,如RDD一般。
Ray同时也不支持分布式对象,如分布式大矩阵,当然可以通过在应用层自行实现(通过一系列的futures)。
对象重建
像Spark,CIEL一样,Ray根据世系来重建对象。除此之外,Ray还支持有状态操作算子(Actor)的重建。
要注意的是,如果世系中包含有状态边,则可能涉及到Actor的重新初始化,并且可能涉及到很长一条世系链的重放。对于某些应用,Ray为了减少Actor的重建时间,加入了checkpoint机制,从checkpoint进行恢复。
为了保证低延迟,如果plasma store满了以后,会通过LRU机制剔除陈旧的对象到磁盘。【到磁盘哪里?】
在Ray中,plasma store即object store挂载在Linux属于tmpfs文件系统的/dev/shm目录上,该目录不在磁盘上,而在内存里。已经存入/dev/shm中的对象不能被其他应用程序使用,但是/dev/shm没被使用的部分可被其他应用程序使用。/dev/shm区域的大小一般是总内存的1/2。即如果你的机器是64G内存,那么此区域只有32G可用,Ray会再保留一点余量,大概用于object store的空间只有26-27GB左右,也就是说,如果Ray处理的数据过大,大到object store都装不下或者在运行时需要频繁evict甚至evict掉其他必要数据的时候,往往程序就会崩溃。
相关工作
下表对相关工作与Ray的相似点与不同点做一总结。
| 比较的系统框架 | 相似点 | 不同点 | |
|---|---|---|---|
| 动态任务图 | CIEL | 动态任务图机制,futures抽象,通过世系容错 | Ray还提供Actor抽象,并实现了全局控制面板,自底向上调度器和采用了内存对象存储而不是文件存储,扩展到Python语言 |
| Dask | 支持动态任务图,wait原语,futures抽象,Python语言 | Dask是中心化调度方式,不提供actor抽象,不提供容错 | |
| 数据流系统 | Hadoop/Spark | Hadoop/Spark计算模型更加限定,实现了BSP执行模型,假设同一阶段的task执行同样的计算,并有着相似的执行时间。Ray还提供Actor抽象,并实现了全局控制面板和调度器。 | |
| Dryad | Dryad放松了Spark的假设,但是也没有实现动态计算图。Ray还提供Actor抽象,并实现了全局控制面板和调度器。 | ||
| Naiad | 对于一些工作流提升了可扩展性。 | 只支持静态计算图。 | |
| Actor系统 | Orleans | 提供虚拟actor-based抽象。 | Orleans可以使actor的多个实例同时运行。需要显式checkpoint,提供at-least-once语义。而Ray提供exactly-once语义。[注] |
| Erlang | Actor抽象。 | 需显式处理容错。Erlang的全局状态存储不适合共享大对象。 | |
| C++ Actor Framework | Actor抽象。 | 需显式处理容错。不支持数据共享。 | |
| 全局控制状态和调度 | SDN | 全局控制状态 | Ray解耦了状态信息存储和逻辑实现(调度器),存储与计算可以独立扩展 |
| Distributed File System,如GFS | 全局控制状态 | Ray解耦了状态信息存储和逻辑实现(调度器),存储与计算可以独立扩展 | |
| Distributed Frameworks (如MapReduce, BOOM) | 全局控制状态 | 与BOOM相比,Ray解耦了状态信息存储和逻辑实现(调度器),存储与计算可以独立扩展 | |
| Resource Management (Omega) | 全局共享状态 | Ray增加了两层调度器来均衡负载,面向毫秒级别的任务调度 | |
| Sparrow | 去中心化调度 | 各调度器自行其是,独立决策 | |
| Mesos | 两级层次调度 | 顶层调度器可能成为瓶颈 | |
| Canary | 去中心化调度 | Canary每个调度器负责计算图的一部分,但不支持动态计算图 | |
| 机器学习框架 | Tensorflow | 面向深度学习,对CPU、GPU资源利用很好,不支持更通用的计算工作流,Tensorflow Fold提供对动态计算图的一些支持,但仍无法全部支持执行时对任务执行进度,任务完成时间和错误的响应而编辑DAG图。支持底层消息传输和同步原语,但是过于底层使得用起来有点像MPI。 | |
| MXNet | 同Tensorflow | ||
| OpenMPI | 高性能 | 很难编程,需要显式处理异构和动态任务图,需要程序员显式处理容错 |
[注] 实时计算/流式计算的三种语义:
At-most-once:每条记录最多只能被处理一次
At-least-once:每条记录最少要被处理一次
Exactly-once:每条记录有且仅被处理一次
总结
蓬勃发展的AI应用对计算框架提出了一些挑战性的需求,为了应对这些需求,本文提出了Ray,实现了全局控制存储和自底向上的调度器,且实现了动态任务图。支持Actor编程和任务并行。这种编程灵活性对于强化学习RL应用尤其重要,因其具有诸多方面的异构性,如执行时间,资源等。Ray提供了一个灵活高性能且易于使用的框架来应对未来的AI应用。


